音声に障がいある人の「声代わり」になれる可能性も
「無言で音声アシスタントが使えるメガネ」が開発。図書館やコンサートも想定

Share

今や音声アシスタント機能がスマートフォンからスマートスピーカーまで利用可能となっているが、それら全てに共通するのが「声を出す必要がある」ということだ。物音がない静かな場所では使いにくくもあり、またプライバシーに関わる情報を声に出すことは情報漏えいのリスクを伴う。
そうしたネックを解消すべく、無言でしゃべった(唇だけ動かした)音声も「聴き取る」ことが可能で、スマートフォンなどを制御できるメガネ型アタッチメントを開発したことを、米コーネル大学の研究者が発表した。
コーネル大学の博士課程に在籍するRuidong Zhang氏は、ワイヤレスイヤホンにより行った同様のプロジェクトや、それ以前のカメラを使ったモデルをベースにしているという。同大学のSmart Computer Interfaces for Future Interactions(SciFi)ラボにおいて開発され、同チームの最新作でもある。
このメガネ型アタッチメントは、小さなマイクとスピーカーを使って、無言で口にした言葉を読み取るものだ。つまり片側のスピーカー2つが発した音は唇などに反射し、それをもう片方に取り付けられたマイク2つが拾う。合計4つの経路から、口の動きを立体的に捉えるわけだ。
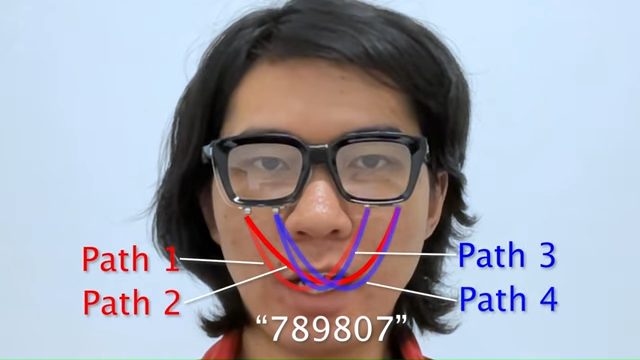
要は音波から周囲の状況や動きを察知する「ソナーメガネ」である。上述のワイヤレスイヤホンを使ったプロジェクトから「音」を、カメラを使ったモデルからは「顔の動きをスキャン」する技術を持ち込んだかたちだ。
ソナーメガネのメリットは、外付けカメラを設置したり、耳に何かを入れたりする必要がないことだ。どこでも場所を選ばず、ワイヤレスイヤホンのように着けたり外したりする手間もない。メガネは顔の一部として、慣れれば存在を意識しなくなることも大きいだろう。
このシステムはユーザーの発話パターンを学習するため、数分間のトレーニングデータ(例えば一連の数字の読み取りなど)を必要とするだけだという。そして準備が整えば、顔全体で音波を送受信し、口の動きを感知しながら、ディープラーニングアルゴリズムにより「約95%の精度」でリアルタイムに音響プロファイルを分析するとのことだ。それにより音楽再生の一時停止やスキップ、スマートフォンに触れずにパスコードを入力、キーボードなしでCADアプリを操作している様子が動画で確認できる。
データ処理はワイヤレス経由でスマートフォンに渡して行われるため、メガネ本体は小型にしやすく低消費電力も実現しやすい。現在のバージョンでは、約10時間のバッテリー持続を実現しているという。さらにデータはスマートフォン内に残らないため、プライバシーに関する懸念もないとのことだ。
開発者のZhang氏は、静かな場所での音楽再生コントロールのほか、大音量のコンサート会場での口述筆記など、ワイヤレスイヤホンでは不可能な使い方を提案している。また音声に障がいのある人が無言でしゃべり(口を動かし)音声合成ソフトに発声してもらうなどの応用も考えられるだろう。
SciFiラボのチームは、コーネル大学の資金提供プログラムを通じて商業化を模索しているという。また顔や目、上半身の動きを追跡するスマートグラスの応用も検討しているとのことだ。
スマートグラスといえばAR(拡張現実)に注目が集まりやすいが、メガネ型は日常的に違和感なく着用できることから、たとえばファーウェイの「Eyewear」のように「スピーカー付きメガネ」に割り切った製品もある。このソナーメガネも高コストにはなりにくいため、そう遠くない将来に製品化されるのかもしれない。
- Source: Cornell Chronicle
- via: Engadget