音を絵で表すスペクトログラムを学習
入力テキストを音楽にするAI「Riffusion」公開。文字を画像化し音に変換
Share

音楽を生成するAIというのはすでに何種類か存在するが、Seth Forsgren氏とHayk Martiros氏が趣味のプロジェクトとして開発した「Riffusion」は、テキストの構文をもとに音の視覚的な表現であるスペクトログラムを作成し、それをオーディオとして再生するという、一風変わったAIモデルだ。
テキスト入力で画像を生成するAIとしては、拡散モデルを使った「DALL・E 2」が少し前に話題になった。そのDALL・E 2と同じ種類の「Stable Diffusion 1.5」が、この音楽生成AIのベースとなっている。
音を画像で表現するスペクトログラムは、X 軸で時間、Y 軸で音の周波数を表し、色で音の振幅を表現する。ForsgrenとMartirosは、サウンドを表現するスペクトログラムのサンプルを大量に作成し、その画像にblues guitar、jazz piano、afrobeatなどといった、関連する音楽を示すワードを紐付けた。
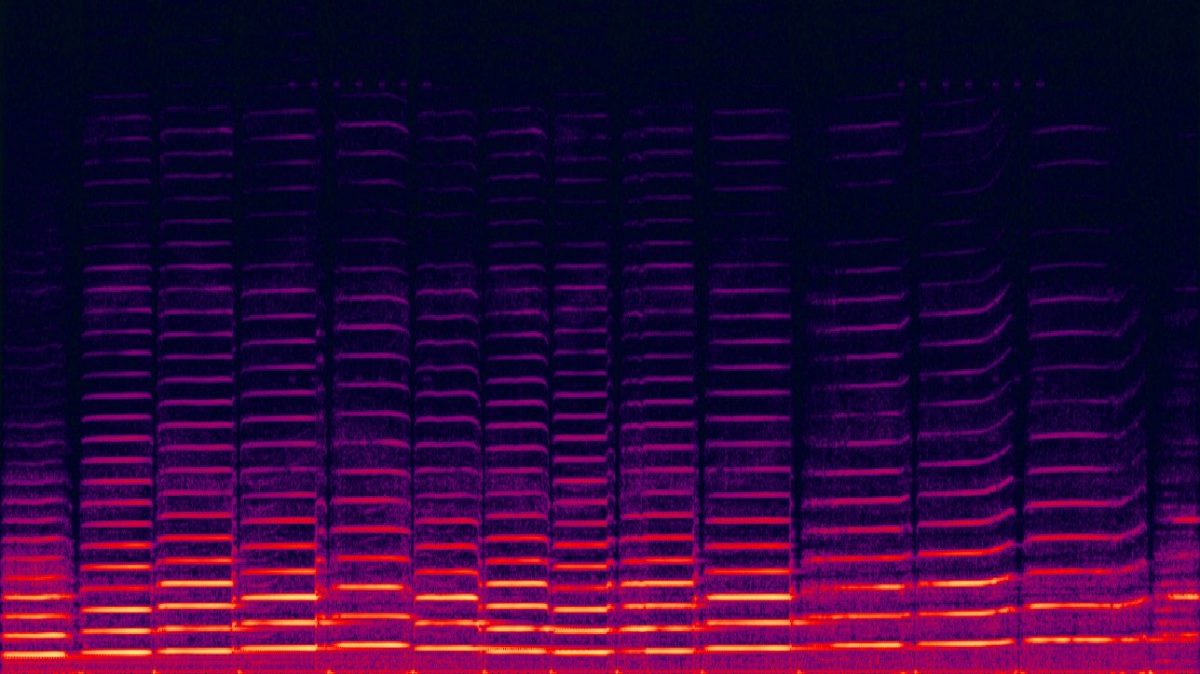
そして、これを使ってAIモデルをトレーニングすることで、ある音が「どのようなものか」「どのように再現したり組み合わせられるか」などといったことが次第にわかり、スペクトログラムと拡散モデルによって、音色を他の音色に変えるようなことも可能になったという。
Riffusionのウェブページでは、画面の左側に、入力されたテキストによって生成されたスペクトログラムが連続して表示され、それをもとにしたオーディオをリアルタイムで再生するようになっている。音楽スタイルを組み合わせてこれまでにない音楽ジャンルを生み出すことも可能だ。
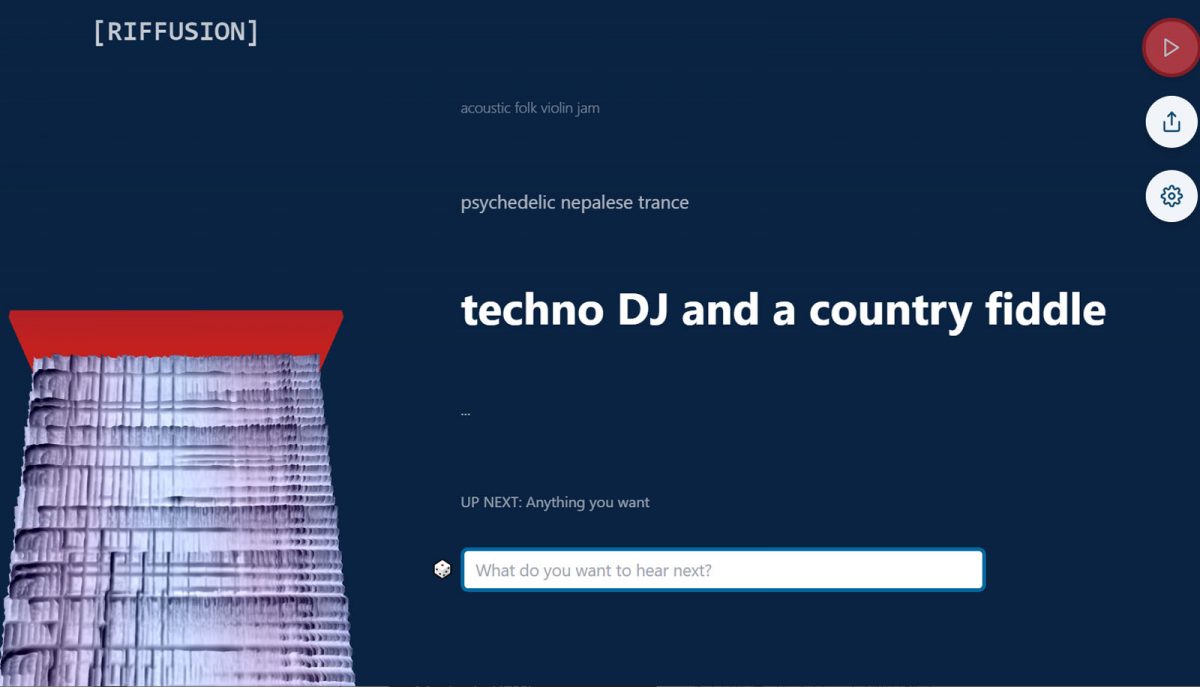
ただ、自分で入力したテキストでは思ったような音楽が出力されないこともある。そのときは、テキスト入力窓の左にあるサイコロのアイコンをクリックすれば、プリセットされた構文が表示されるのでこれを実行してみると良いだろう。きっと、ああなるほどな、と思える音楽が再生できるはずだ。
Forsgren氏は「Haykと私は単に音楽が好きなもの同士というだけだったので、Stable DiffusionというAIがオーディオに変換できるほど、ちゃんとしたスペクトログラムを生成できるのかもわからなかった」とTechCrunchに述べ「ひとつのアイデアが次のアイデアへと次々につながっていった」結果、Riffusionができあがったとしている。
音楽生成AIモデルはRiffusionが初めてというわけではない。少し前にはロンドンのAIスタートアップHarmonaiが、やはりStable Diffusionをベースに拡散モデルを使った「Dance Diffusion」なる音楽生成AIを公開している。また仕組みは違うが、2020年にはOpenAIが、ニューラルネットワークで音楽を生成する「Jukebox」を発表していた。さらにノンストップで音楽を生成するSoundrawのようなサービスもすでに存在する。
RiffusionはこれらのAIに比べると、もっとホビーの領域にあるものであり、生成される音楽もまだまだリスニング用途に耐えるものではない。それでも潜在拡散モデルの応用例としては、注目を集めそうだ。
- Source: Riffusion
- via: Ars Technica