想定の範囲外から攻めます
弱い囲碁プログラムで、トップクラスの強豪AIを打ち負かす研究
Share

DeepMindの囲碁AI「AlphaGo」が人間の囲碁世界チャンピオンを下し、最強の座に就いたのは2016年のことだったが、あれから時は流れ、最近は人間のトップランカー棋士と互角の実力を持つオープンソース囲碁AI「KataGo」が人気を博している。
最強とまではいかなくともトップクラスの強さを誇るKataGoも、自分自身を相手に何百万もの対局を経験させることで強化されている。しかし、あらゆる手筋をカバーするにはまだまだ経験不足な部分もあり、トレーニングに使用した棋譜や自分自身との対戦では出てこないような、定石から大きく外れた奇手への対応には経験が不足していると考えられる。
カリフォルニア大学バークレー校の研究者Adam Gleave氏らは、初心者レベルの囲碁プログラムにこうした奇襲戦法を教え込むことで、一般人に負けるへっぽこさながら、トップクラスの囲碁AIにはめっぽう強い囲碁AIを構築する研究を行い、論文にまとめた。
Gleave氏は、ニューラルネットワークとモンテカルロ木探索(MCTS)と呼ばれるアルゴリズムを組み合わせた「敵対的ポリシー」を用いたプログラムを開発した。このプログラム(黒石)は対局中に盤面の一隅(サンプル図では右上)に地を作って強力に固め、残りの領域は相手(KataGo、白石)の自由にさせつつ、相手が取りやすい位置に黒石をポツポツと配置する。
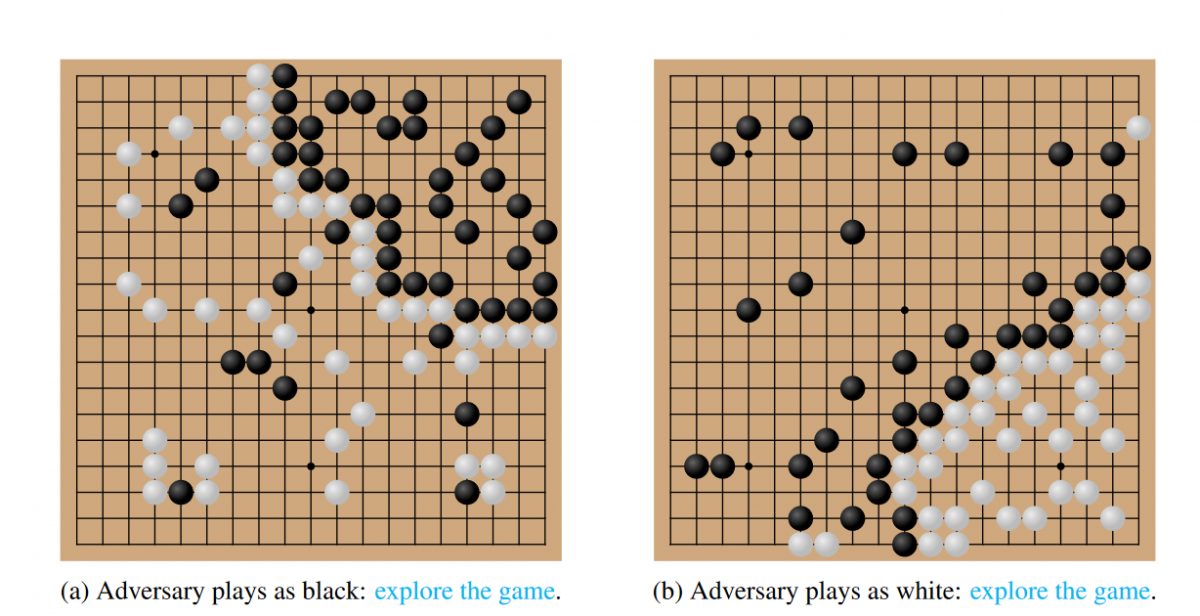
このような配置にすることで、KataGoは広々としたエリアを支配しているため、自分が圧倒的に有利と思い込んでしまうのだそう。しかし、実際にはKataGoが思うように得点を重ねられない構図に持ち込まれているという算段だ。
KataGoは自分が勝っていると信じ込んでいるので、ある程度対局が進めば自分の手の際にパスをするようになる。こうなったら、実は自分が有利だとわかっている敵対的ポリシーのプログラムも、パスで応えて終局にすることで、決着が付く。この時点でKataGoは自分が勝ったと思っているのだが、実際は右上を固めたプログラム側が勝利する。
敵対的ポリシーのプログラムは、こうしてKataGoを打ち負かすことができる。しかしこのプログラムの目的はKataGoの虚を突くことだけなので、囲碁の実力的には並み以下、人間のアマチュア棋士にも簡単に負けてしまうというのが面白いところだ。
研究者らは、「KataGoは多くの新しい戦略に対してうまく対処できるが、強化学習の際に見たことのある手と違う手筋であればあるほど、その実力は弱まってしまう」と語る。そして今回のプログラムは「KataGoが特に苦手とする戦略を見つけ出したが、(このような手筋は)ほかにもたくさんありそうだ」とし、今回と同じようなことはほとんどすべてのディープラーニング式囲碁AIで起こりうるとしている。
研究では、囲碁に限らなくとも、このように予測の範囲を超えたケースを与えることで、AIを欺くことができる可能性があるとも指摘している。たとえば自動運転AIが、まったくありえないような、完全に想定外の事象に路上で出くわしたとき、どのような対応をするかは、そのときでないとわからない。
Gleave氏は「この研究は通常状態における性能をテストするだけでなく、極端で最悪なケースでの故障モードを発見できるよう、AIシステムの自動化されたテスト内容を改善する必要性を強調している」と述べている。
- Source: arXiv.org
- via: Ars Technica