最小バージョンはPixel 8 Proに搭載
Google、次世代AIモデル「Gemini」発表。GPT-4をほぼ凌駕したとアピール

Share

Googleは12月6日(現地時間)、次世代AIモデル「Gemini」を発表した。これは5月の開発者会議「Google I/O 2023」で予告していたものだ。
GoogleはGeminiを「弊社の最大かつ最も有能なAIモデル」と説明。テキストやプログラムコード、オーディオや画像、動画をシームレスに理解し、横断的に操作し、組み合わせることが可能だという。こうしたマルチモーダル推論機能は、何十万もの文書から洞察を引き出し「科学から金融まで多くの分野で、デジタルスピードで新たなブレークスルーを実現するのに役立つ」と謳われている
スンダー・ピチャイCEOとGoogle傘下のAI開発企業ディープマインドのデミス・ハサビスCEOによれば、これはAIモデルにおける大きな飛躍であり、最終的には実質的にGoogle製品すべてに影響を与えることになるという。
Geminiは単一のAIモデルではなく、「Gemini Ultra」「Gemini Pro」「Gemini Nano」という3つのサイズで提供される。
まずGemini Nanoは、モバイルでのオンデバイス(クラウドに依存しない)タスクに最適化した軽量モデル。現時点ではPixel 8 Proが唯一の対応モデルであり、レコーダーアプリの自動要約機能と、キーボードアプリGboardのスマートリプライに活かされる。どちらも、12月のPixel Feature Dropの一部として即日利用が可能だ。ただし、現時点では英語のみの対応となる。
次にGemini Proは、GoogleのチャットボットBardを通じて提供が始まっている。より高度な推論や計画、理解が可能となり、「Bardのローンチ以来、最大のアップデート」とのこと。こちらも今は英語のみ対応しているが、近い将来、新たな言語や地域もサポートする予定だ。
最後にGemini Ultraは、主にデータセンターや企業アプリケーション向けの最も強力なモデルだ。まずレッドチームテスト(外部からの攻撃に対する防御能力をテストし、脆弱性を特定する)を行った上に、「選ばれた顧客、開発者、パートナー、安全性と責任の専門家」によるテストとフィードバックを要するため、少なくとも2024年までは利用できないという。
その「洗練された推論」能力を誇示するため、GoogleはGeminiが20万件の科学研究論文を消化させ、1時間ほどでデータを要約するデモを行った。さらにPython、Java、C++、Goの「高品質なコードを理解し、説明し、生成」できるとのこと。要はプログラムコードを読んだ上で自ら書けるということだ。
さらに性能面では、GoogleはLLM(大規模言語モデル)の研究開発で広く使われる32の学術的ベンチマークのうち30において、「現在の最先端の結果」すなわちOpenAIのGPT-4を上回ることを示した。ただしハサビス氏は、非常に僅差に留まっている指標もあると認めている。
特に強調しているのはGemini Ultraが「MMLU(大規模マルチタスク言語理解)において人間の専門家を上回った最初のモデル」という点だ。
このベンチマークは「数学、物理学、歴史、法律、医学、倫理など57の科目を組み合わせて世界知識と問題解決能力の両方」をテストするものであり、スコアは90.0%だったとのこと。それに対して、GPT-4は86.4%である。
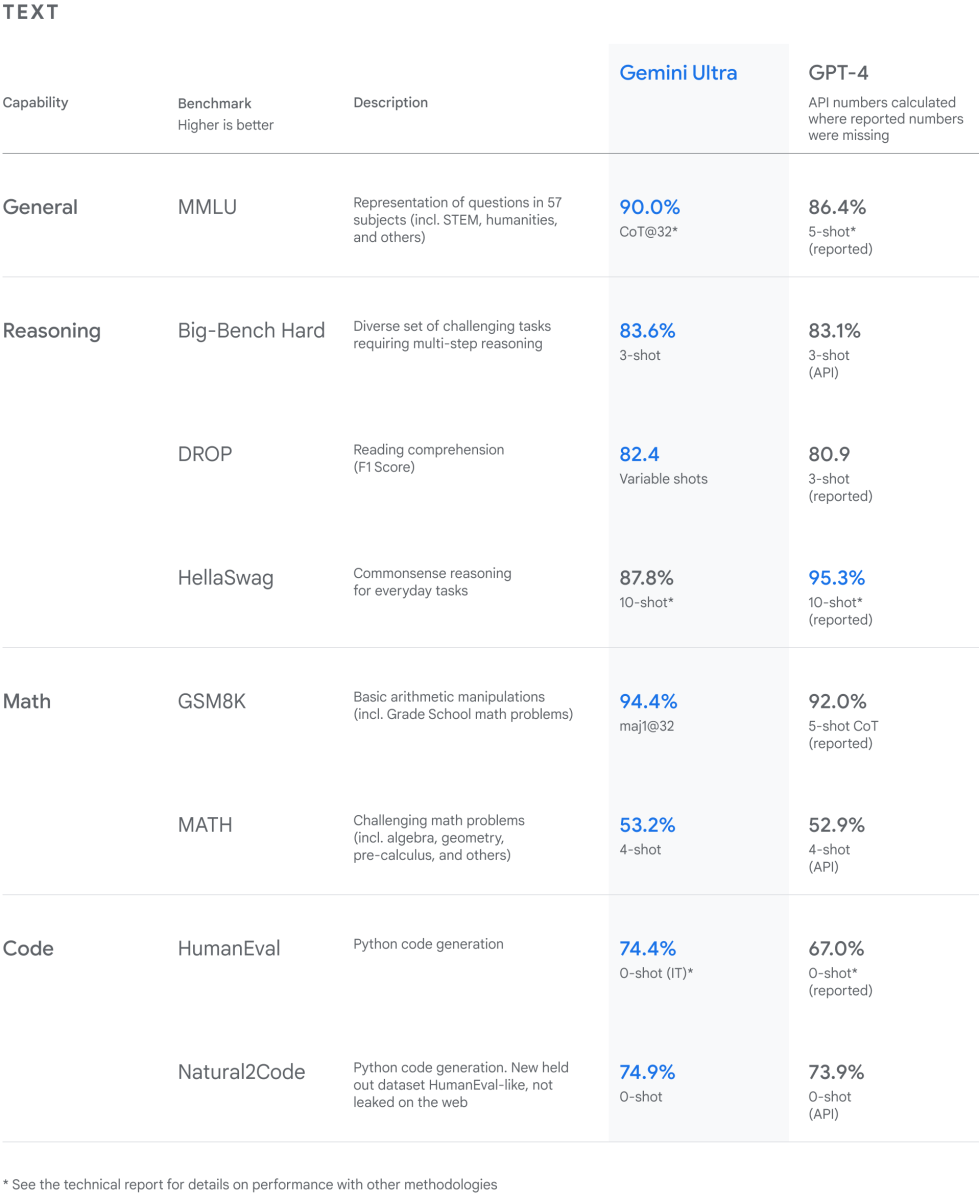
数値の上ではわずかな差だが、Gemini Ultraの優位性は動画や音声も理解できるマルチモーダル性にあるという。テキストや画像などを区別せず、あらゆる入力やセンサーから可能な限り多くのデータを収集し、多様な反応が返せるというわけだ。
実際にGemini Ultraが稼働するのは少し先のことで、どこまで役立つかは未知数だ。Pixel 8 Proで利用できるNanoはスケールが違いすぎるためUltraの手がかりにはなりそうにないが、日本語を含めた様々な言語で利用できる日を待ちたいところだ。
- Source: Google Blog
- via: The Verge